材料準備
- AmebaPro2 [ AMB82 MINI ] x 1
範例說明
介紹
在本例中,我們將使用 Ameba Pro2 開發板來檢測 521 種不同類型的音頻,例如語音、動物聲音、警報等等。
流程
在“File”->“Examples”->“AmebaNN”->“AudioClassification”中打開音頻分類範例。
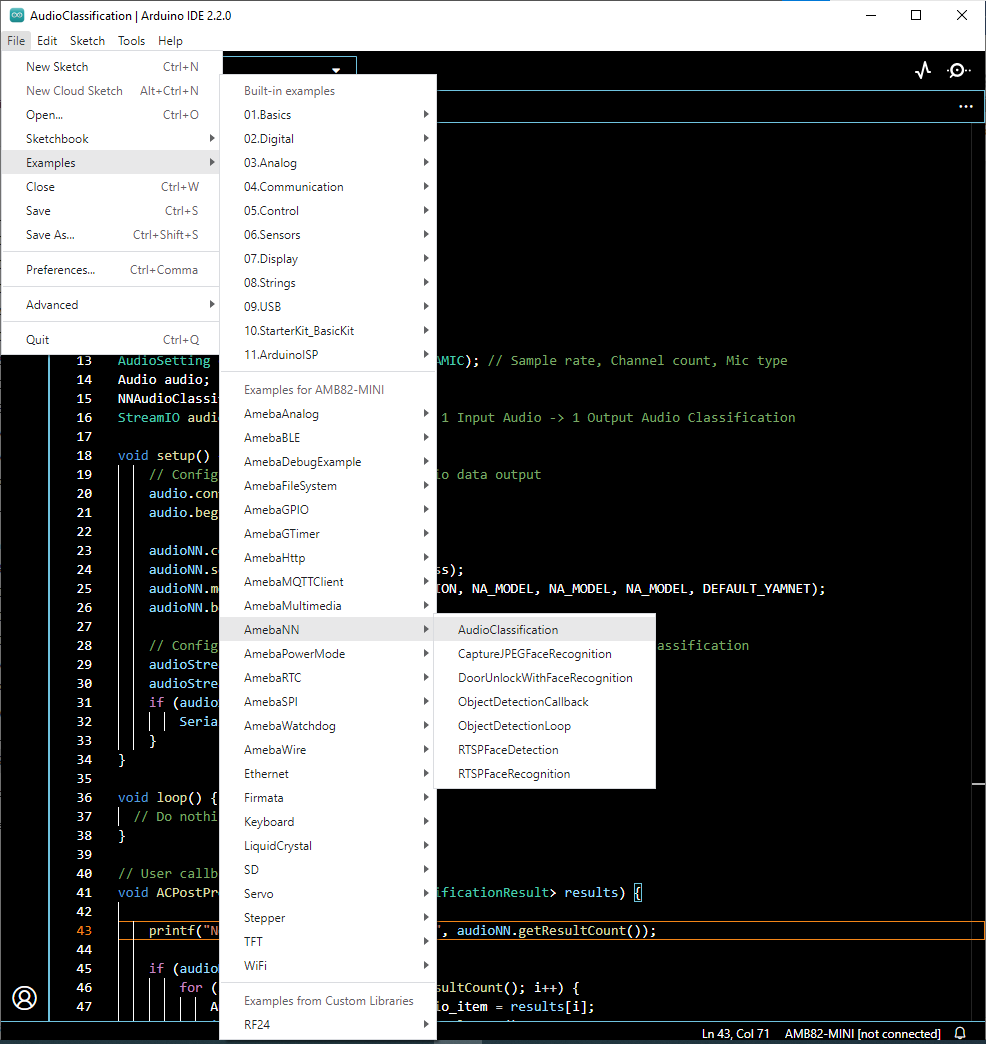
使用以黃色標記的 modelSelect() 函式選擇Neural Network (NN) 工作和模型。 該函式有 5 個參數:Neural Network工作、物體偵測模型、人臉偵測模型、人臉辨識模型和音頻分類模型。 如果您選擇的Neural Network工作不需要它們,請替換為“NA_MODEL”。 請注意,必須在調用 begin() 之前調用 modelSelect()。
有效的Neural Network: OBJECT_DETECTION, FACE_DETECTION, FACE_RECOGNITION, AUDIO_CLASSIFICATION
有效的物體偵測模型:
YOLOv3 模型: DEFAULT_YOLOV3TINY, CUSTOMIZED_YOLOV3TINY
YOLOv4 模型: DEFAULT_YOLOV4TINY, CUSTOMIZED_YOLOV4TINY
YOLOv7 模型: DEFAULT_YOLOV7TINY, CUSTOMIZED_YOLOV7TINY
有效的人臉偵測模型: DEFAULT_SCRFD, CUSTOMIZED_SCRFD
有效的人臉辨識模型: DEFAULT_MOBILEFACENET, CUSTOMIZED_MOBILEFACENET
有效的音頻分類模型: DEFAULT_YAMNET, CUSTOMIZED_YAMNET
如果您想使用自己的 NN 模型,請選擇自定義選項(例如,CUSTOMIZED_YOLOV4TINY/ CUSTOMIZED_SCRFD/ CUSTOMIZED_MOBILEFACENET/ CUSTOMIZED_YAMNET)。 要了解轉換 AI 模型的過程,請參閱此處。 此外,請參閱此處以了解如何安裝和使用轉換後的模型。

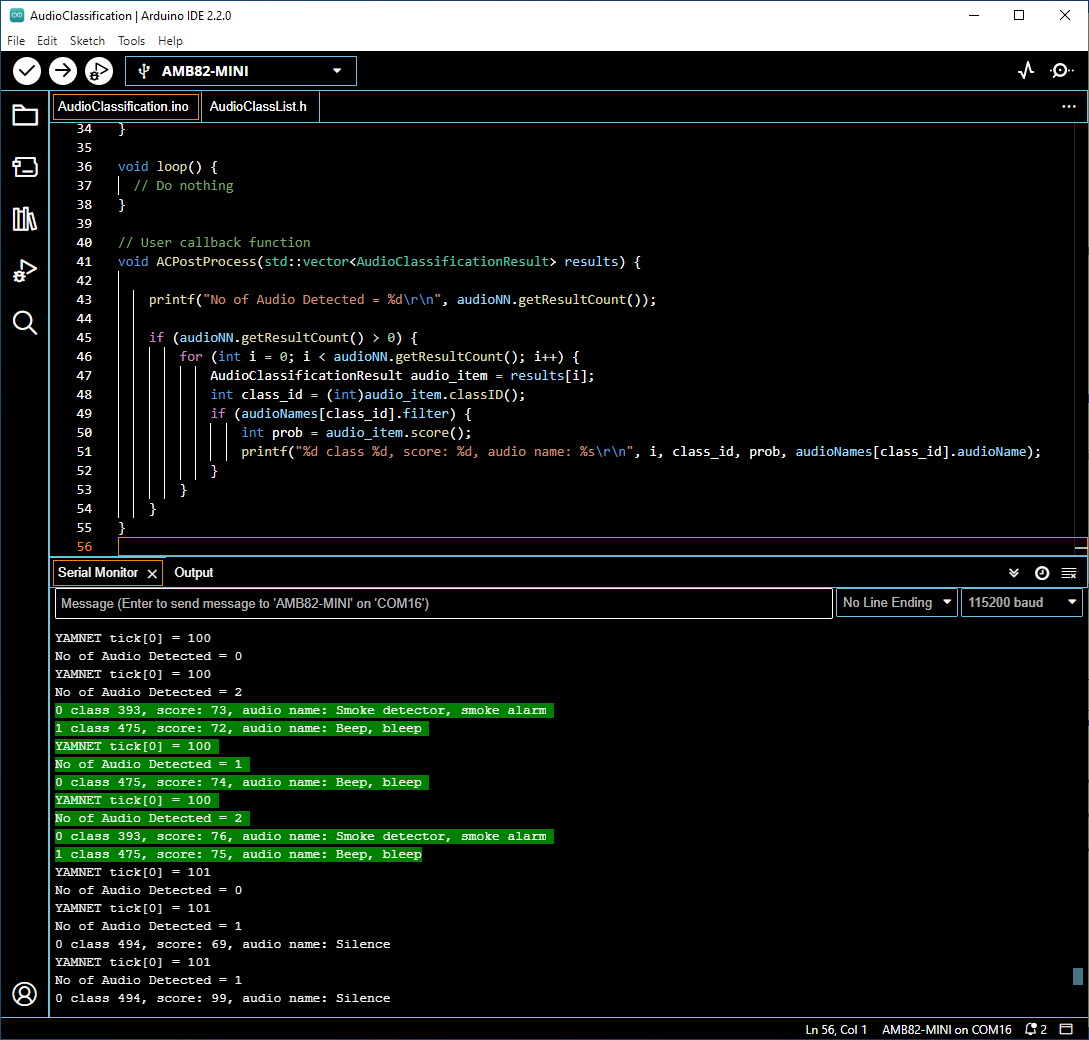
編譯代碼並將其上傳到Ameba。 按下重置按鈕後,板載麥克風將開始錄製音頻。
當沒有檢測到音頻時,它將被識別為Serial Monitor中顯示的“Silence”類別。

當板載麥克風錄製警報等音頻時,識別後結果將顯示在Serial monitor中。
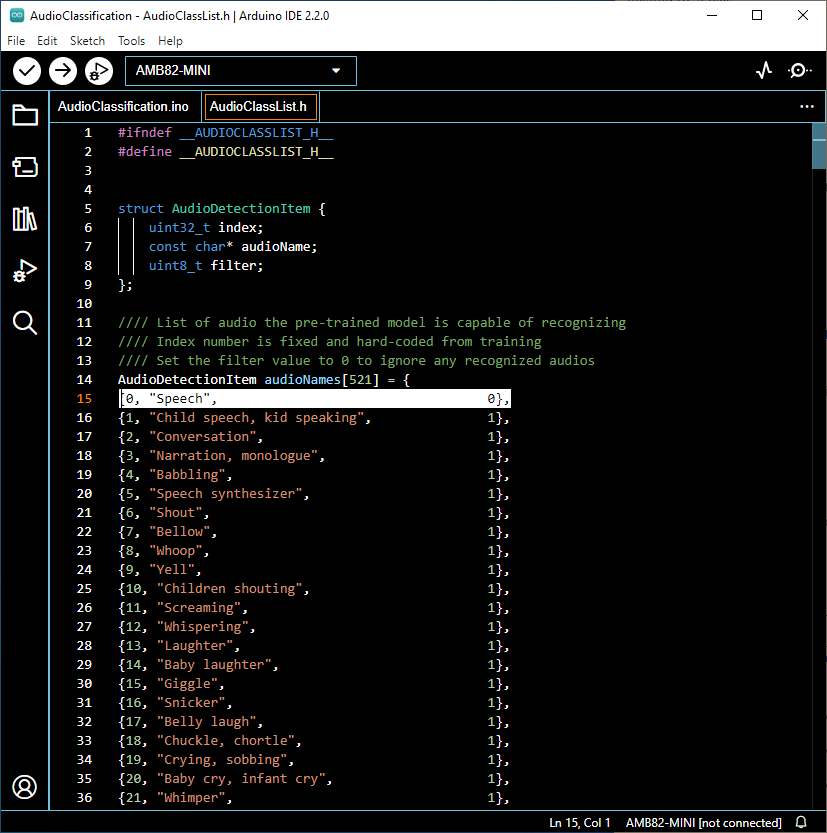
默認的預先訓練模型總共可以識別 521 種不同類型的音頻。 音頻可以在 AudioClassList.h 中找到。 每個音頻類別的索引號(也稱為class ID)是固定的,不應更改。 要停用某些音頻的識別,請將filter設置為 0。例如,將filter設置為 0 以排除檢測語音。